


Recent News
- Karen Bjorndal elected AAAS Lifetime Fellow!
April 23, 2024
 Congratulations to Department of Biology Professor Karen Bjorndal who was elected to the American Association for the Advancement of Sciences ...
Congratulations to Department of Biology Professor Karen Bjorndal who was elected to the American Association for the Advancement of Sciences ... - Ed Braun publishes in Nature AND PNAS on the same day!
April 11, 2024
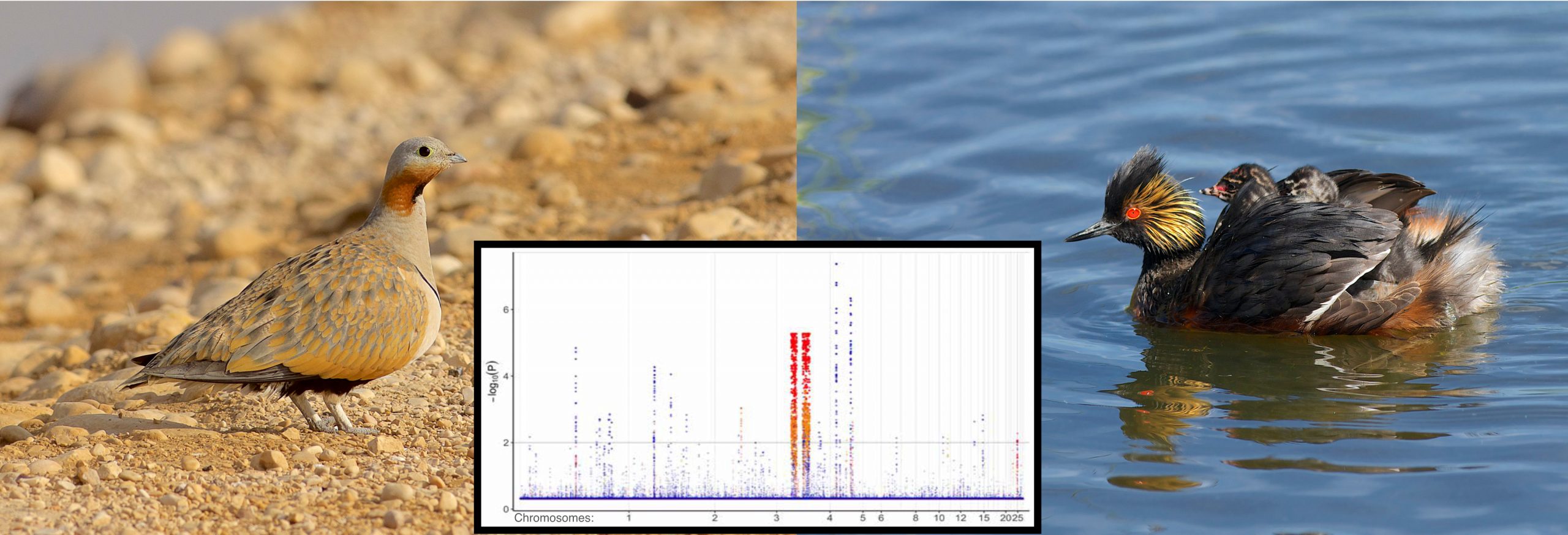
 Congratulations to Ed Braun, publishing related manuscripts in both Nature on the same day – April 1st! Ed’s ...
Congratulations to Ed Braun, publishing related manuscripts in both Nature on the same day – April 1st! Ed’s ... - Amanda Subalusky and Christopher Dutton Receive Press for Research Programs in ACS Central Science
February 22, 2024
 UF Biology Assistant Professors Amanda Subalusky and Christopher Dutton received some popular press coverage for their overall research programs in ...
UF Biology Assistant Professors Amanda Subalusky and Christopher Dutton received some popular press coverage for their overall research programs in ... - Study By Todd Palmer And Colleagues Shows Link Between Invasive Ants and Ecological Domino Effect
February 22, 2024
 A study by Todd Palmer and colleagues published in Science (January 25th), makes the link between invasive big-headed ants and ...
A study by Todd Palmer and colleagues published in Science (January 25th), makes the link between invasive big-headed ants and ... - Stand Up & Holler – Giving Day
January 31, 2024
Please consider supporting the Department of Biology’s efforts to provide experiential learning opportunities through research and Immersion courses with a ...